1. 개요
N-gram이란 텍스트, 바이너리 등 전체 문자열을 N 값 만큼 서브스트링(Sub-String)으로 나누어 통계학적으로 사용한 방법을 의미한다. "기계학습"이라는 단어를 2-gram 기준으로 적용하면 "기계", "계학", "학습" 이라는 3가지 하위 문자열들이 각각 빈도수 1로 생성되게 된다. N-gram은 "귀납 학습" 범주에 속하는 학습 방법으로 구체적인 사례를 통해 공통점을 추출하는 형태이다. 이렇게 N-gram은 조각난 문자열을 통해 발생하는 출현 빈도를 암기(학습)하여 사용하는 것이다.
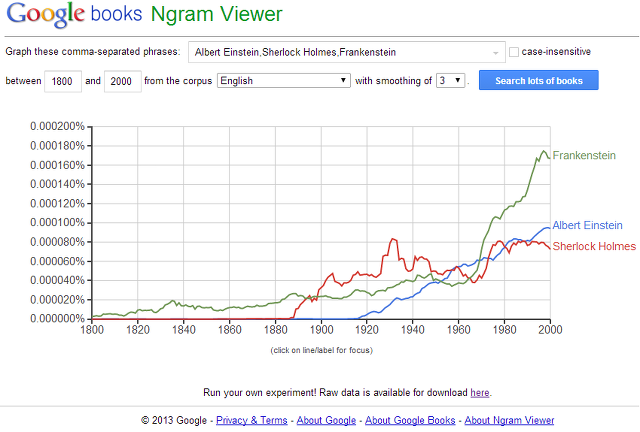
이 기법을 사용하는 대표적인 사례는 구글 북스 엔그램(Google Books N-gram)이 있다. 구글이 모든 책들을 디지털화 시키면서 함께 진행하는 프로젝트로 문화의 전개 방향이라던가, 시대가 보려는 관심사 등 보다 더 정밀한 데이터를 얻을 수 있다는데에서 사용된다. 가령 예를 들면 그 시대에 "셜록 홈즈"가 인기가 없었으나, 향후 다양한 책에서 "셜록 홈즈"라는 단어를 얼만큼 사용되었는가를 보면 앞으로의 "셜록 홈즈"가 시대에 미칠 영향력을 알 수 있다는 것이다.

그 외 언어 인식, 색인 방법, 검색 등 다양한 분야에서 활용하고 있다.
보안적인 관점에서는 악성코드 바이너리 파일을 테스트하여 적정선의 N의 값을 이용, N-gram을 사용하여 좀 더 신뢰성이 높은 시그니처로 활용되는 방안도 연구되고 있다.
2. 참조
- http://shadowxx.egloos.com/10780577
- 만들면서 배우는 기계 학습
반응형
'Information Technology > Machine Learning' 카테고리의 다른 글
| [기계 학습] 파라미터 조정과 학습 (0) | 2014.04.07 |
|---|---|
| [기계 학습] 기계 학습의 역사 2 (0) | 2014.04.06 |
| [기계 학습] 기계 학습의 역사 1 (0) | 2014.04.02 |
| [기계 학습] 기계학습이란? (0) | 2014.03.31 |