단순히 방화벽에서 하루동안 발생하는 로그가 1TB라면 어떻게 처리할 것인가? 수많은 인력을 통해 매일 분석할 수도 없는 노릇이다. 이러한 대용량 데이터를 처리하기 위해서는 빅데이터에 의존할 수 밖에 없다. 여기서 설명하는 빅데이터는 하둡이며 분산파일처리 시스템이다. 최근 드라이브의 용량은 상승하였지만 전송 속도는 약 100MB/s 수준에 머물러 있기 때문에 1TB의 디스크의 전체를 읽으려면 2시간 반이라는 계산이된다. 그래서 빅데이터에서 분산 파일 시스템의 경우 여러 디스크로부터 데이터를 읽어 처리 속도를 상승시킨다. 1TB의 크기의 데이터를 1/10 (100GB)만을 사용한 10개의 디스크로 병렬로 구현하여 읽는다면 1000초 즉 16~17분 만에 읽을 수 있게 된다.
이렇게 데이터를 병렬로 읽고 쓰려면 다음과 같은 고민을 해야한다.
1. 하드웨어 장애
많은 하드웨어를 사용할 수록 하드웨어의 장애가 발생할 확률이 높아진다. 그래서 일반적으로 데이터 손실을 막기 위해 대상 데이터를 여러 곳에 복제하는 것(RAID) 처럼 중복 데이터 복사본을 관리하여 장애가 발생하면 복사본을 참조하도록 운영한다. 하둡이 사용하는 파일시스템(HDFS(Hadoop Distributed FileSystem))은 조금은 다른 방식을 사용하고 있지만, RAID는 이와 같은 방식으로 동작한다.
2. 결합 방식
하나의 디스크로부터 읽은 데이터는 다른 9개의 디스크로부터의 데이터가 병합될 필요가 있다. 분산된 데이터를 다중 출처라 하고 이 데이터들을 병합할 수 있도록 지원해야 하지만, 이 작업의 정합성은 계속 도전해야할 과제이다. 하둡에서 맵리듀스(MapReduce)가 있는데, 이는 디스크의 읽고 쓰는 문제를 추상화해서 키(key)와 값(value)에 대한 계산으로 변환시켜 놓는 2004년에 발표한 소프트웨어 프로그래밍 프레임워크이다. Map과 Reduce 두 종류의 계산을 통해 병합(Mixing) 인터페이스가 제공된다. 이 프로그래밍 모델은 당연히 안정성을 보장해야 한다.

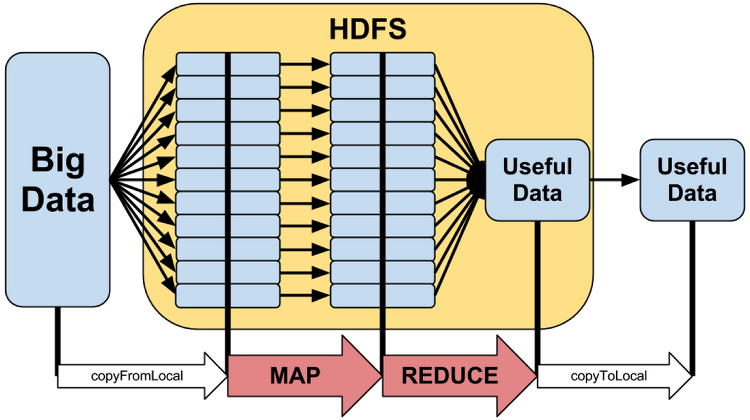
위 그림과 같이 빅 데이터를 분산 파일 시스템인 HDFS로 분할하여 저장하는데 맵(Map)과 리듀스(Reduce)과정을 거쳐 유용한 데이터를 추출해 낸다. 모든 데이터를 처리하는 과정은 병렬로 구성된다.
빅 데이터의 특징
빅 데이터의 특징은 3v로 정리 된다. 3v는 Volume, Velocity, Variety로 구분된다.
Volume (양, 용량)
- Terabytes
- Records
- Transactions
- Tables, files
Velocity (속도)
- Batch
- Near time
- Real time
- Streams
Variety (다양성)
- Structured
- Unstructured
- Semistructured
- All the above
-참조
- Hadoop 완벽가이드, 한빛미디어
- http://www.glennklockwood.com/di/hadoop-overview.php
- http://hothobbang.tistory.com/41
- http://sasbigdata.com/18
'Information Technology > Bigdata' 카테고리의 다른 글
| How to install Hadoop 2.2.0 (0) | 2014.02.12 |
|---|